SimTeG: A Frustratingly Simple Approach Improves Textual Graph Learning
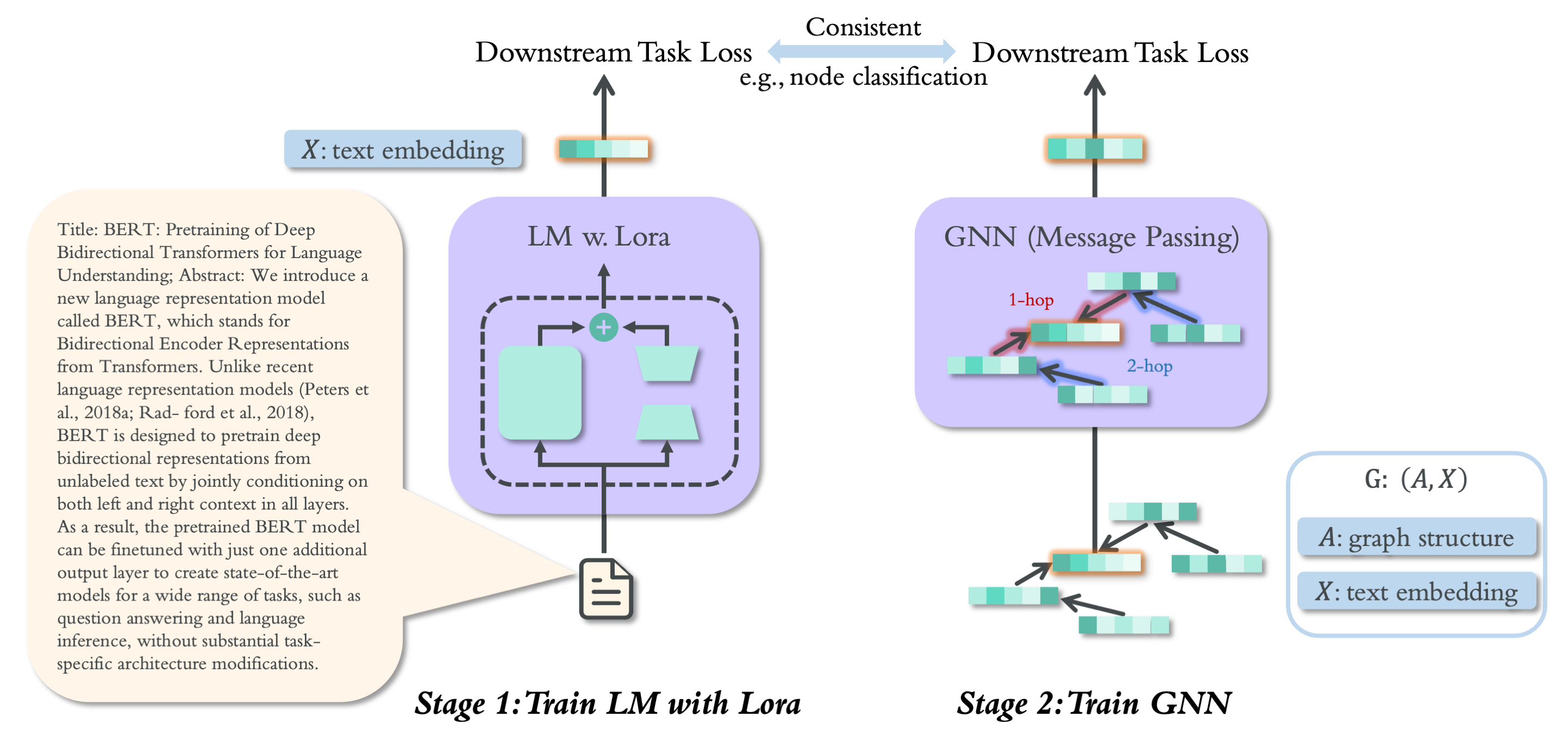
Textual graphs (TGs) are graphs whose nodes correspond to text (sentences or documents), which are widely prevalent. The representation learning of TGs involves two stages: (i) unsupervised feature extraction and (ii) supervised graph representation learning. In recent years, extensive efforts have been devoted to the latter stage, where Graph Neural Networks (GNNs) have dominated. However, the former stage for most existing graph benchmarks still relies on traditional feature engineering techniques. More recently, with the rapid development of language models (LMs), researchers have focused on leveraging LMs to facilitate the learning of TGs, either by jointly training them in a computationally intensive framework (merging the two stages), or designing complex self-supervised training tasks for feature extraction (enhancing the first stage). In this work, we present SimTeG, a frustratingly Simple approach for Textual Graph learning that does not innovate in frameworks, models, and tasks. Instead, we first perform supervised parameter-efficient fine-tuning (PEFT) on a pre-trained LM on the downstream task, such as node classification. We then generate node embeddings using the last hidden states of finetuned LM. These derived features can be further utilized by any GNN for training on the same task. We evaluate our approach on two fundamental graph representation learning tasks: node classification and link prediction. Through extensive experiments, we show that our approach significantly improves the performance of various GNNs on multiple graph benchmarks.